
Demandbase consolidates firmographics data service architecture by migrating from Elasticsearch to StarRocks-based Celerdata


Key Takeaways
- Architectural consolidation: Demandbase migrated its Firmographics Data Service from a split Elasticsearch/Celerdata architecture to a unified Celerdata instance, enabling complex cross-entity joins on datasets exceeding 400 million records.
- OLAP over search: The move leveraged the StarRocks engine (via Celerdata) to enable vectorized execution for high-speed joins, overcoming limitations in Elasticsearch’s document-oriented architecture.
- Feature parity engineering: The team partnered with the database vendor to introduce native ngram_search capabilities, replacing Elasticsearch autocomplete while maintaining sub-100 ms latency.
- Risk mitigation: A “Tap-Compare” (shadow mode) strategy validated the migration by routing 10% of live traffic to the new system without impacting end users.
- Pipeline modernization and trade-offs: The write path was refactored to a CDC pipeline, improving data flow but introducing friction in schema evolution and field mapping.
- Query engine resilience: Intermittent OOM failures were mitigated through query restructuring and vendor collaboration, resulting in improved stability under high load.
- Client-side optimization wins: Payload right-sizing and UI caching reduced API call volume from 480K to 80K, significantly improving system performance.
Engineers at Demandbase migrated their Firmographics Data Service from Elasticsearch to Celerdata to enable cross-database joins and unify their data architecture. The migration was driven by the need to perform high-performance filtering across two datasets: the global Demandbase database and customer-specific account data.
By consolidating storage engines, the team eliminated scalability bottlenecks associated with cross-database processing while maintaining latency parity for critical search and autocomplete features.
The challenge: The “data silo” problem
The Firmographics Data Service is the backbone of the Demandbase ecosystem. It manages the essential “firmographic” data—the organizational equivalent of demographics—including industry, revenue, and employment data. This service powers core features of the DB1 platform, such as company and contact pages and list-building tools, as well as external offerings like Demandbase Data Integrity and Public APIs. It is responsible for handling high-volume read operations, including searches, fetches, bucket aggregations, and fuzzy searches on company and contact data.
The legacy architecture relied on a split storage model:
- Elasticsearch (ES): Hosted the global Demandbase directory using a single index with a parent-child relationship (Company as parent, Employment as child).
- Celerdata: Hosted specific account and contact information for current customers.
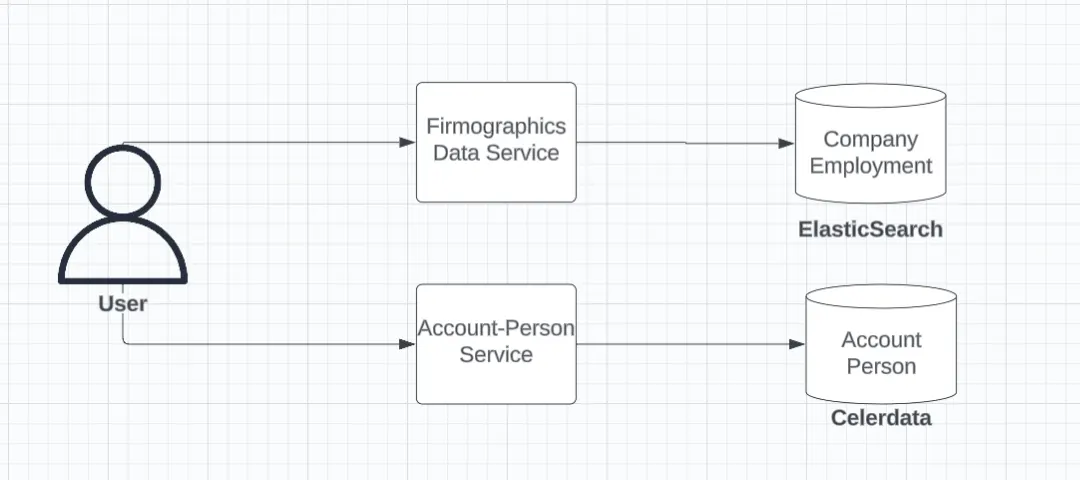 User fetching firmographics data from Elasticsearch and account-person data from Celerdata
User fetching firmographics data from Elasticsearch and account-person data from Celerdata
Technical debt accrued when product requirements shifted to demand complex filtering across both datasets simultaneously—specifically, performing right or left joins to extract “company-only” data or “known contacts” intersecting both global and customer lists.
The engineering team evaluated three distinct approaches to solve this:
- Consolidation in Elasticsearch: This required migrating customer data into ES. However, supporting complex joins across four distinct entities within Elasticsearch proved architecturally infeasible due to the limitations of ES join types and performance overhead.
- Application-side joins: This involved fetching data from both sources and joining it in memory. This was rejected due to the high memory footprint required to hold millions of records and the computational cost of sorting large datasets at the application layer.
- Consolidation in Celerdata: Moving global directory data into Celerdata offered the necessary SQL join capabilities but initially lacked native support for specific search features the Firmographics Data Service relied on, such as autocomplete.
The architecture: Enabling search on an OLAP engine
The team selected Celerdata, the enterprise platform built on the open-source StarRocks engine, as the unified datastore, effectively moving from a search engine (ES) to a real-time analytics database.
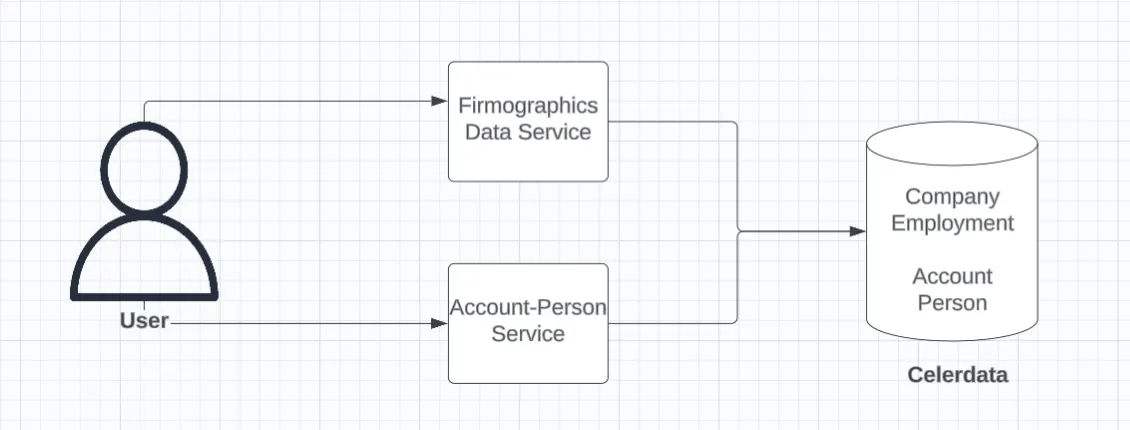 User fetching both firmographics and account-person data from Celerdata
User fetching both firmographics and account-person data from Celerdata
Advanced query optimization and feature parity
The team moved Firmographics search from Elasticsearch (built for search) to StarRocks (built for real-time analytics). That meant identifying the key feature differences and building practical equivalents so the user experience stayed the same—without keeping Elasticsearch in the loop.
1. Feature differences and implementation approach
| Area | Elasticsearch Capability | How the Team Addressed It in StarRocks |
|---|---|---|
| Text Processing (Analyzers vs. Ingest-Time Tokenization) | Built-in analyzers automatically handle stopwords, diacritics, stemming, and token filters at index/query time. | Text processing moved to the ingestion layer. Strings are pre-tokenized and normalized in application code using Lucene, and “search-ready” versions are stored in StarRocks. |
| Exact Match + Sorting (Multi-fields vs. Multiple Columns) | Supports multiple “views” of the same field (analyzed for search, keyword for exact match, normalized for sorting) within a single mapping. | Modeled explicitly using separate columns: raw/exact value, sort-normalized value, and tokenized/search value. |
| Complex Data Structures (Nested + Relationships) | Native support for nested objects and parent/child relationships within the index. | Implemented using SQL-native modeling with normalized tables and joins for strict correctness; JSON/arrays used where appropriate. |
| Ranking and Relevance | Built-in relevance scoring, boosting, and ranking via Query DSL. | Ranking made explicit and application-driven. Elasticsearch-style boosting recreated in SQL using weighted expressions combining ngram_search similarity scores with popularity and business signals for deterministic ranking. |
2. Two-phase querying: The fix for complex search latency
Initial translations of Elasticsearch queries to CelerData caused latency regressions for complex search endpoints. These queries attempted to fetch all fields, apply all filters, and perform joins in a single pass—an execution pattern better suited to Elasticsearch’s document-oriented access model than a columnar OLAP engine.
Why this failed in CelerData:
CelerData is columnar and scan-optimized. Wide row fetches, early joins, and unnecessary column access significantly increased scan cost and memory pressure.
Solution: Two-phase query execution
- Phase 1 – Search and Identify: Run a lightweight, column-pruned query that applies search conditions and filters, returning only entity IDs.
- Phase 2 – Fetch Details: Fetch full entity data for the filtered IDs in a separate query.
Why this worked:
- Phase 1 scans only a small subset of columns, aligning with columnar storage strengths
- Phase 2 limits full-row access to a small ID set, avoiding large table scans
- Reduced join fan-out and intermediate result sizes
Result:
Performance Improvement within CelerData: latency reduced from ~30s (initial, unoptimized CelerData queries) to ~1.2s after optimizations (~98% reduction).
Additional optimizations:
- Independent queries executed concurrently
- Unlinked queries parallelized to better utilize available resources
This approach significantly reduced scan volume and improved response times without sacrificing correctness.
3. Recreating autocomplete and global search on StarRocks
Autocomplete was the biggest feature gap in the migration. Elasticsearch supports autocomplete-style search naturally because it is designed for text lookup. StarRocks did not originally have the n-gram style search needed for “type-ahead” experiences.
To close this gap, the team partnered with CelerData and helped get a native ngram_search capability added, including case-insensitive support. However, edge n-gram style behavior (commonly used in Elasticsearch for prefix autocomplete) still wasn’t available in StarRocks.
To mimic the same user experience, team implemented a hybrid approach:
- LIKE-based prefix matching on preprocessed (Lucene-normalized) fields to emulate edge n-gram behavior
- Ngram_search to improve matching quality beyond simple prefixes
- Custom scoring and ordering to closely reproduce Elasticsearch’s autocomplete relevance
This combination allowed the team to preserve the existing autocomplete behavior while fully removing Elasticsearch from the serving path.
For global search, joining across million-row tables proved expensive. Instead of large joins:
- Subqueries were used strategically to filter datasets before combining results
- This significantly reduced intermediate result sizes and avoided unnecessary join amplification
Performance Improvement within CelerData: latency reduced from ~6s (initial, unoptimized CelerData queries) to ~2.5s after optimizations (~60% reduction).
4. Optimizing array filters with tokenization and LIKE matching
Several fields contained large arrays that were frequently queried using array_contains. In practice, this resulted in poor performance in StarRocks for high-cardinality arrays.
To resolve this:
- Large array fields were converted into space-separated string representations
- LIKE-based matching was used instead of array_contains
Performance Improvement within CelerData: latency reduced from ~4s (initial, unoptimized CelerData queries) to ~1s after optimizations (~75% reduction).
While this required careful tokenization and boundary handling, the change resulted in dramatic query performance improvements, especially under high concurrency.
5. Making aggregations run at low latency
Aggregating list-type
- List-type aggregations could not be easily combined with standard field aggregations in a single query
The solution involved:
- Running separate aggregation queries for list-based fields and scalar fields
- Executing these aggregation queries in parallel to minimize overall response time
- Avoiding joins wherever possible to reduce query execution overhead
Performance Improvement within CelerData: latency reduced from ~40s (initial, unoptimized CelerData queries) to ~800ms after optimizations (~98% reduction).
This approach preserved correctness while keeping aggregation latency within acceptable bounds.
Cost and operational impact
Direct infrastructure savings: Consolidating on CelerData eliminated the need for dedicated, self-managed Elasticsearch clusters on AWS, resulting in a significant reduction in infrastructure run-rate costs.
Operational bandwidth savings: Removing Elasticsearch reduced ongoing maintenance overhead (cluster operations, scaling, upgrades, on-call). This translated to ~8 weeks of one engineer’s time per year freed up from ES upkeep.
Workflow simplification savings: Decommissioning Elasticsearch also removed the separate ES indexing workflow (pipelines, reindex jobs, backfills), reducing both compute spend and the engineering time spent monitoring and troubleshooting indexing health.
Monitoring and reliability overhead reduction: Fewer moving parts (no dual datastore + indexing lag to watch) lowered the cost and effort spent on alerting, dashboards, and incident response tied to index freshness and search cluster stability.
Results & lessons learned
The migration successfully unified data sources and enabled complex joins without application-side overhead.
Full Traffic moved from Elasticesearch to Celerdata on 20 Nov 20:30 IST

Notice that the average latency remain unaffected even with the traffic switch

The retrospective highlighted several key outcomes:
- Simplification: Single datastore reduced architectural complexity
- Latency parity: Maintained performance despite moving off a search engine
- CDC trade-offs: Improved pipeline but introduced schema evolution challenges
- Improved resilience: Query restructuring eliminated OOM issues
- Client optimizations: Reduced unnecessary data transfer
- Massive load reduction: API calls dropped from 480K to 80K through caching and workflow improvements
This migration demonstrates that modern OLAP systems can successfully replace traditional search engines—if teams are willing to rethink query patterns, data modeling, and feature implementation.
Rather than attempting a one-to-one replacement of Elasticsearch, Demandbase leaned into the strengths of a columnar analytics engine. By redesigning queries, rebuilding search capabilities, and collaborating closely with their vendor, the team achieved both architectural simplification and performance gains.
The result is a more scalable, maintainable, and cost-efficient system that not only meets existing requirements but creates a stronger foundation for future innovation.
Related content


We have updated our Privacy Notice. Please click here for details.